
HTTP là một giao thức cho phép tìm nạp các tài nguyên, chẳng hạn như tài liệu HTML. Nó là nền tảng của bất kỳ trao đổi dữ liệu nào trên Web và nó là một giao thức khách – máy chủ, có nghĩa là các yêu cầu được khởi tạo bởi người nhận, thường là trình duyệt Web. Một tài liệu hoàn chỉnh được tạo lại từ các tài liệu con khác nhau được tìm nạp, chẳng hạn như văn bản, mô tả bố cục, hình ảnh, video, tập lệnh và hơn thế nữa .
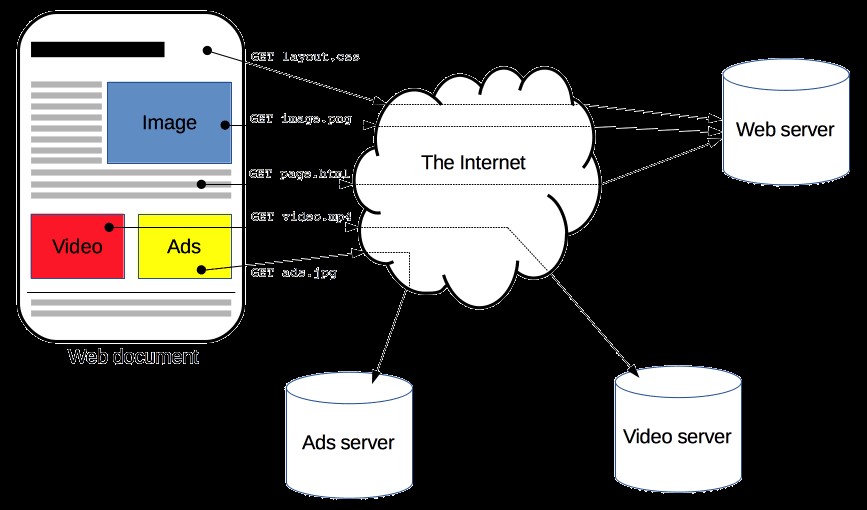
Máy khách và máy chủ giao tiếp bằng cách trao đổi các thông điệp riêng lẻ (trái ngược với một luồng dữ liệu). Các thông báo được gửi bởi máy khách, thường là một trình duyệt Web, được gọi là yêu cầu và các thông báo được gửi bởi máy chủ dưới dạng câu trả lời được gọi là phản hồi .
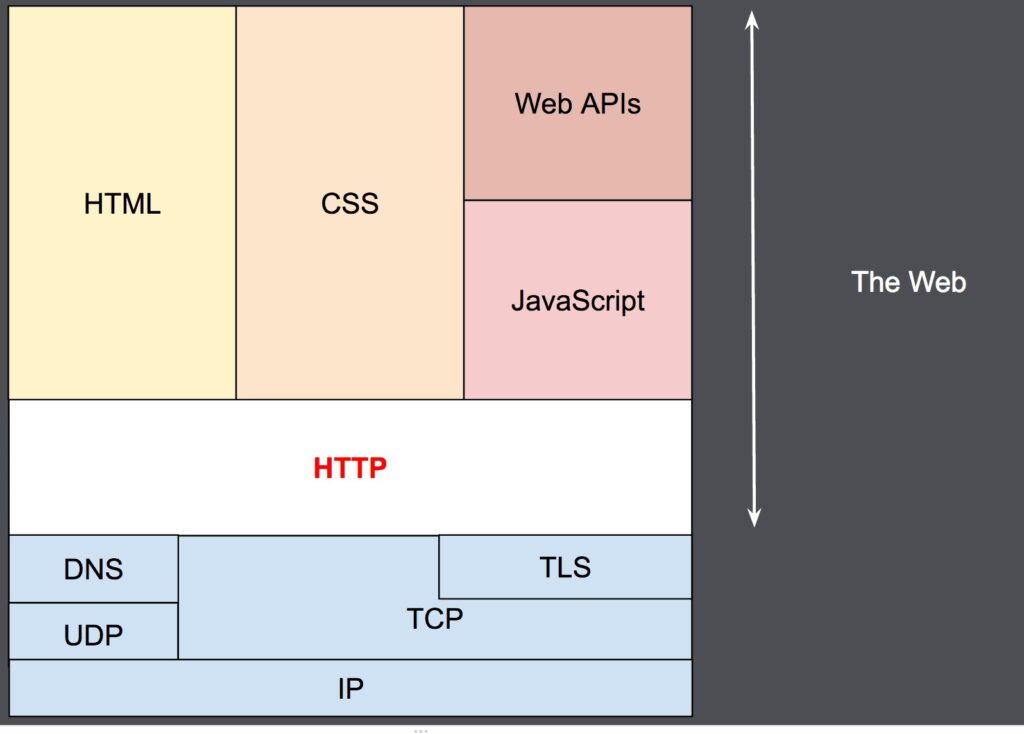
Được thiết kế vào đầu những năm 1990, HTTP là một giao thức có thể mở rộng đã phát triển theo thời gian. Nó là một giao thức lớp ứng dụng được gửi qua TCP hoặc qua kết nối TCP được mã hóa bằng TLS , mặc dù về mặt lý thuyết, có thể sử dụng bất kỳ giao thức truyền tải đáng tin cậy nào. Do khả năng mở rộng của nó, nó được sử dụng để không chỉ tìm nạp các tài liệu siêu văn bản mà còn cả hình ảnh và video hoặc để đăng nội dung lên máy chủ, như với các kết quả biểu mẫu HTML. HTTP cũng có thể được sử dụng để tìm nạp các phần của tài liệu nhằm cập nhật các trang Web theo yêu cầu.
Nội dung chính
Các thành phần của hệ thống dựa trên HTTP
HTTP là một giao thức máy khách-máy chủ: các yêu cầu được gửi bởi một thực thể, tác nhân người dùng (hoặc một proxy thay mặt cho nó). Hầu hết thời gian tác nhân người dùng là một trình duyệt Web, nhưng nó có thể là bất cứ thứ gì, chẳng hạn như một rô-bốt thu thập thông tin trên Web để điền và duy trì chỉ mục của công cụ tìm kiếm.
Mỗi yêu cầu riêng lẻ được gửi đến một máy chủ, máy chủ sẽ xử lý nó và cung cấp một câu trả lời, được gọi là phản hồi. Giữa máy khách và máy chủ có rất nhiều thực thể, được gọi chung là proxy, thực hiện các hoạt động khác nhau và hoạt động như cổng hoặc bộ nhớ đệm chẳng hạn.

Trên thực tế, có nhiều máy tính hơn giữa trình duyệt và máy chủ xử lý yêu cầu: có bộ định tuyến, modem, v.v. Nhờ thiết kế phân lớp của Web, chúng được ẩn trong mạng và các lớp truyền tải. HTTP ở trên cùng, ở lớp ứng dụng. Mặc dù quan trọng để chẩn đoán sự cố mạng, các lớp bên dưới hầu hết không liên quan đến mô tả của HTTP.
Khách hàng: tác nhân người dùng
Tác nhân người dùng là bất kỳ công cụ nào hoạt động nhân danh người dùng. Vai trò này chủ yếu được thực hiện bởi trình duyệt Web; các khả năng khác là các chương trình được sử dụng bởi các kỹ sư và nhà phát triển Web để gỡ lỗi các ứng dụng của họ.
Trình duyệt luôn là thực thể khởi tạo yêu cầu. Nó không bao giờ là máy chủ (mặc dù một số cơ chế đã được thêm vào trong nhiều năm để mô phỏng các thông báo do máy chủ khởi tạo).
Để trình bày một trang Web, trình duyệt sẽ gửi một yêu cầu ban đầu để tìm nạp tài liệu HTML đại diện cho trang đó. Sau đó, nó phân tích cú pháp tệp này, đưa ra các yêu cầu bổ sung tương ứng với các tập lệnh thực thi, thông tin bố cục (CSS) để hiển thị và các tài nguyên phụ có trong trang (thường là hình ảnh và video). Sau đó, trình duyệt Web kết hợp các tài nguyên này để trình bày cho người dùng một tài liệu hoàn chỉnh, trang Web. Các tập lệnh do trình duyệt thực thi có thể lấy thêm tài nguyên trong các giai đoạn sau và trình duyệt cập nhật trang Web tương ứng.
Trang Web là một tài liệu siêu văn bản. Điều này có nghĩa là một số phần của văn bản được hiển thị là các liên kết có thể được kích hoạt (thường bằng cách nhấp chuột) để tìm nạp một trang Web mới, cho phép người dùng điều hướng tác nhân người dùng của họ và điều hướng qua Web. Trình duyệt dịch các chỉ dẫn này trong các yêu cầu HTTP và diễn giải thêm các phản hồi HTTP để cung cấp cho người dùng một phản hồi rõ ràng.
Máy chủ web
Ở phía đối diện của kênh liên lạc, là máy chủ, phục vụ tài liệu theo yêu cầu của khách hàng. Máy chủ hầu như chỉ xuất hiện dưới dạng một máy duy nhất: điều này là do nó thực sự có thể là một tập hợp các máy chủ, chia sẻ tải (cân bằng tải) hoặc một phần mềm phức tạp thẩm vấn các máy tính khác (như bộ nhớ cache, máy chủ DB hoặc thương mại điện tử máy chủ), tạo toàn bộ hoặc một phần tài liệu theo yêu cầu.
Một máy chủ không nhất thiết phải là một máy duy nhất, nhưng một số phiên bản phần mềm máy chủ có thể được lưu trữ trên cùng một máy. Với HTTP/1.1 và Host Header, chúng thậm chí có thể chia sẻ cùng một địa chỉ IP.
Proxy
Giữa trình duyệt Web và máy chủ, nhiều máy tính và máy móc chuyển tiếp các thông điệp HTTP. Do cấu trúc phân lớp của ngăn xếp Web, hầu hết chúng hoạt động ở cấp độ truyền tải, mạng hoặc vật lý, trở nên trong suốt ở lớp HTTP và có khả năng tác động đáng kể đến hiệu suất. Những người hoạt động ở các lớp ứng dụng thường được gọi là proxy. Chúng có thể minh bạch, chuyển tiếp các yêu cầu mà chúng nhận được mà không thay đổi chúng theo bất kỳ cách nào hoặc không minh bạch, trong trường hợp đó, chúng sẽ thay đổi yêu cầu theo một cách nào đó trước khi chuyển nó đến máy chủ. Proxy có thể thực hiện nhiều chức năng:
- Bộ nhớ đệm (bộ đệm có thể là công khai hoặc riêng tư, như bộ đệm của trình duyệt)
- Lọc (như quét chống vi-rút hoặc kiểm soát của phụ huynh)
- Cân bằng tải (để cho phép nhiều máy chủ phục vụ các yêu cầu khác nhau)
- Xác thực (để kiểm soát quyền truy cập vào các tài nguyên khác nhau)
- Ghi nhật ký (cho phép lưu trữ thông tin lịch sử)

Các khía cạnh cơ bản của HTTP
HTTP đơn giản
HTTP thường được thiết kế để đơn giản và con người có thể đọc được, ngay cả khi có thêm sự phức tạp được giới thiệu trong HTTP / 2 bằng cách đóng gói các thông điệp HTTP thành các khung. Con người có thể đọc và hiểu các thông điệp HTTP, cung cấp khả năng kiểm tra dễ dàng hơn cho các nhà phát triển và giảm độ phức tạp cho người mới.
HTTP có thể mở rộng
Được giới thiệu trong HTTP/1.0, HTTP Header giúp giao thức này dễ dàng mở rộng và thử nghiệm. Chức năng mới thậm chí có thể được giới thiệu bằng một thỏa thuận đơn giản giữa máy khách và máy chủ về ngữ nghĩa của tiêu đề mới.
HTTP là không trạng thái, nhưng không phải là không phiên
HTTP không trạng thái: không có liên kết giữa hai yêu cầu được thực hiện liên tiếp trên cùng một kết nối. Điều này ngay lập tức có khả năng trở thành vấn đề đối với người dùng cố gắng tương tác với các trang nhất định một cách mạch lạc, chẳng hạn như sử dụng giỏ mua hàng thương mại điện tử. Nhưng trong khi bản thân lõi của HTTP là không trạng thái, cookie HTTP cho phép sử dụng các phiên trạng thái. Sử dụng khả năng mở rộng tiêu đề, các Cookie HTTP được thêm vào quy trình làm việc, cho phép tạo phiên trên mỗi yêu cầu HTTP để chia sẻ cùng một ngữ cảnh hoặc cùng một trạng thái.
HTTP và kết nối
Một kết nối được kiểm soát ở lớp truyền tải và do đó về cơ bản nằm ngoài phạm vi của HTTP. Mặc dù HTTP không yêu cầu giao thức truyền tải cơ bản phải dựa trên kết nối; chỉ yêu cầu nó phải đáng tin cậy hoặc không bị mất thông báo (vì vậy, ít nhất là xuất hiện một lỗi). Trong số hai giao thức truyền tải phổ biến nhất trên Internet, TCP là đáng tin cậy và UDP thì không. HTTP do đó dựa trên tiêu chuẩn TCP dựa trên kết nối.
Trước khi máy khách và máy chủ có thể trao đổi một cặp yêu cầu / phản hồi HTTP, chúng phải thiết lập kết nối TCP, một quá trình yêu cầu một số chuyến đi vòng. Hoạt động mặc định của HTTP / 1.0 là mở một kết nối TCP riêng biệt cho từng cặp yêu cầu / phản hồi HTTP. Điều này kém hiệu quả hơn so với việc chia sẻ một kết nối TCP đơn lẻ khi nhiều yêu cầu được gửi liên tiếp.
Để giảm thiểu lỗ hổng này, HTTP / 1.1 đã giới thiệu pipelining (được chứng minh là khó thực hiện) và các kết nối liên tục : kết nối TCP bên dưới có thể được kiểm soát một phần bằng cách sử dụng Connection header. HTTP / 2 đã tiến một bước xa hơn bằng cách ghép các thông báo qua một kết nối duy nhất, giúp giữ cho kết nối ấm và hiệu quả hơn.
Các thử nghiệm đang được tiến hành để thiết kế một giao thức truyền tải tốt hơn phù hợp hơn với HTTP. Ví dụ: Google đang thử nghiệm với QUIC được xây dựng dựa trên UDP để cung cấp một giao thức truyền tải đáng tin cậy và hiệu quả hơn.
Những gì có thể được kiểm soát bởi HTTP
Tính chất có thể mở rộng này của HTTP, theo thời gian, được phép kiểm soát nhiều hơn và chức năng của Web. Bộ nhớ đệm hoặc phương pháp xác thực là các chức năng được xử lý sớm trong lịch sử HTTP. Ngược lại, khả năng nới lỏng ràng buộc nguồn gốc chỉ mới được bổ sung vào những năm 2010.
Dưới đây là danh sách các tính năng phổ biến có thể điều khiển bằng HTTP.
- Bộ đệm ẩn: Cách HTTP có thể kiểm soát các tài liệu được lưu trong bộ đệm. Máy chủ có thể hướng dẫn proxy và máy khách, về những gì cần lưu vào bộ nhớ cache và trong bao lâu. Máy khách có thể hướng dẫn proxy bộ đệm trung gian bỏ qua tài liệu được lưu trữ.
- Giảm bớt ràng buộc về nguồn gốc: Để ngăn chặn việc theo dõi và các hành vi xâm phạm quyền riêng tư khác, các trình duyệt Web thực thi sự tách biệt chặt chẽ giữa các trang Web. Chỉ các trang từ cùng một nguồn gốc mới có thể truy cập tất cả thông tin của một trang Web. Mặc dù ràng buộc như vậy là một gánh nặng đối với máy chủ, nhưng tiêu đề HTTP có thể giảm bớt sự phân tách nghiêm ngặt này ở phía máy chủ, cho phép một tài liệu trở thành một tập hợp thông tin có nguồn gốc từ các miền khác nhau; thậm chí có thể có những lý do liên quan đến bảo mật để làm như vậy.
- Xác thực: Một số trang có thể được bảo vệ để chỉ những người dùng cụ thể mới có thể truy cập chúng. Xác thực cơ bản có thể được cung cấp bởi HTTP, bằng cách sử dụng WWW-Authenticate và các tiêu đề tương tự hoặc bằng cách thiết lập một phiên cụ thể bằng cách sử dụng các cookie HTTP.
- Proxy và đường hầm: Máy chủ hoặc máy khách thường nằm trên mạng nội bộ và ẩn địa chỉ IP thực của chúng với các máy tính khác. Các yêu cầu HTTP sau đó sẽ đi qua proxy để vượt qua rào cản mạng này. Không phải tất cả proxy đều là proxy HTTP. Ví dụ, giao thức SOCKS hoạt động ở cấp độ thấp hơn. Các giao thức khác, như ftp, có thể được xử lý bởi các proxy này.
- Phiên: Sử dụng cookie HTTP cho phép bạn liên kết các yêu cầu với trạng thái của máy chủ. Điều này tạo ra các phiên, mặc dù HTTP cơ bản là một giao thức ít trạng thái. Điều này không chỉ hữu ích cho các giỏ mua hàng thương mại điện tử mà còn cho bất kỳ trang web nào cho phép người dùng định cấu hình đầu ra.
Luồng HTTP
Khi một khách hàng muốn giao tiếp với một máy chủ, máy chủ cuối cùng hoặc một proxy trung gian, nó sẽ thực hiện các bước sau:
1. Mở kết nối TCP: Kết nối TCP được sử dụng để gửi một hoặc nhiều yêu cầu và nhận câu trả lời. Máy khách có thể mở một kết nối mới, sử dụng lại kết nối hiện có hoặc mở một số kết nối TCP tới các máy chủ.
2. Gửi tin nhắn HTTP: Các tin nhắn HTTP (trước HTTP / 2) là con người có thể đọc được. Với HTTP / 2, các thông điệp đơn giản này được gói gọn trong các khung, khiến chúng không thể đọc trực tiếp, nhưng nguyên tắc vẫn như cũ. Ví dụ:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
3. Đọc phản hồi do máy chủ gửi, chẳng hạn như:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: “51142bc1-7449-479b075b2891b”
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html… (here comes the 29769 bytes of the requested web page)
4. Đóng hoặc sử dụng lại kết nối cho các yêu cầu khác.
Nếu HTTP pipelining được kích hoạt, một số yêu cầu có thể được gửi mà không cần đợi phản hồi đầu tiên được nhận đầy đủ. HTTP pipelining đã được chứng minh là khó triển khai trong các mạng hiện có, nơi các phần mềm cũ cùng tồn tại với các phiên bản hiện đại. HTTP pipelining đã được thay thế bằng HTTP / 2 với các yêu cầu ghép kênh mạnh mẽ hơn trong một khung.
Tin nhắn HTTP
Thông báo HTTP, như được định nghĩa trong HTTP / 1.1 trở về trước, là con người có thể đọc được. Trong HTTP / 2, những thông điệp này được nhúng vào một cấu trúc nhị phân, một khung , cho phép tối ưu hóa như nén tiêu đề và ghép kênh. Ngay cả khi chỉ một phần của thông báo HTTP ban đầu được gửi trong phiên bản HTTP này, ngữ nghĩa của mỗi thông báo là không thay đổi và khách hàng sẽ tạo lại (hầu như) yêu cầu HTTP / 1.1 ban đầu. Do đó, sẽ rất hữu ích khi hiểu các thông điệp HTTP / 2 ở định dạng HTTP / 1.1.
Có hai loại thông điệp HTTP, yêu cầu và phản hồi, mỗi loại có định dạng riêng.
Yêu cầu
Một yêu cầu HTTP mẫu:
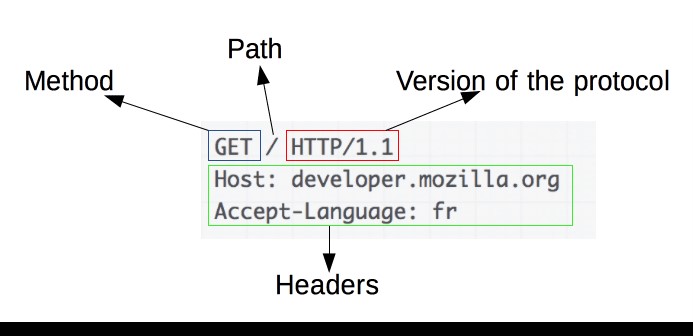
Yêu cầu bao gồm các yếu tố sau:
- Một phương thức HTTP , thường là một động từ like GET, POST hoặc một danh từ like OPTIONS hoặc HEAD xác định thao tác mà khách hàng muốn thực hiện. Thông thường, khách hàng muốn tìm nạp tài nguyên (sử dụng GET) hoặc đăng giá trị của biểu mẫu HTML (sử dụng POST), mặc dù có thể cần nhiều thao tác hơn trong các trường hợp khác.
- Đường dẫn của tài nguyên để tìm nạp; URL của tài nguyên bị loại bỏ khỏi các phần tử hiển nhiên khỏi ngữ cảnh, ví dụ như không có giao thức ( http://), miền (tại đây, developer.mozilla.org) hoặc cổng TCP (tại đây, 80).
- Phiên bản của giao thức HTTP.
- Các tiêu đề tùy chọn truyền tải thông tin bổ sung cho các máy chủ.
- Hoặc một phần nội dung, đối với một số phương thức như POST, tương tự như các phương thức trong phản hồi, chứa tài nguyên được gửi.
Phản hồi
Một phản hồi ví dụ:
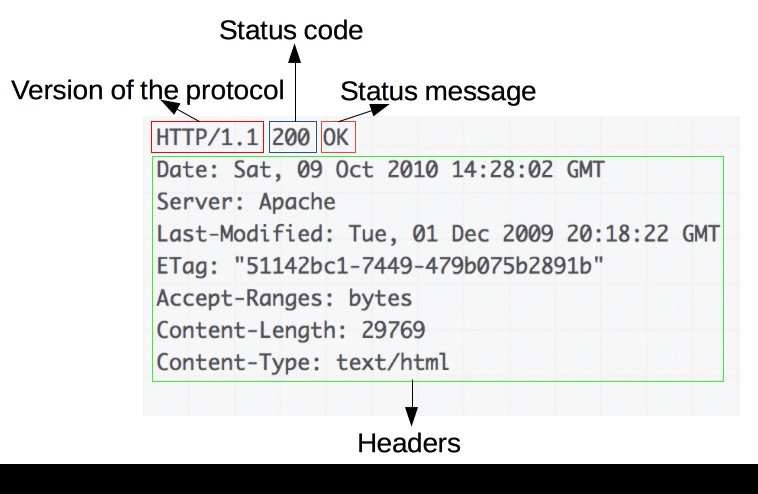
Câu trả lời bao gồm các yếu tố sau:
- Phiên bản của giao thức HTTP mà họ tuân theo.
- Một mã trạng thái , cho thấy nếu yêu cầu thành công, hay không, và tại sao.
- Một thông báo trạng thái, một mô tả ngắn không có thẩm quyền về mã trạng thái.
- Tiêu đề HTTP , giống như tiêu đề cho các yêu cầu.
- Theo tùy chọn, nội dung chứa tài nguyên đã tìm nạp.
API dựa trên HTTP
API được sử dụng phổ biến nhất dựa trên HTTP là XMLHttpRequest API, có thể được sử dụng để trao đổi dữ liệu giữa tác nhân người dùng và máy chủ. Hiện đại Fetch API cung cấp các tính năng tương tự với một bộ tính năng mạnh mẽ và linh hoạt hơn.
Một API khác, các sự kiện do máy chủ gửi , là dịch vụ một chiều cho phép máy chủ gửi các sự kiện đến máy khách, sử dụng HTTP làm cơ chế truyền tải. Sử dụng EventSource giao diện, máy khách mở một kết nối và thiết lập các trình xử lý sự kiện. Trình duyệt máy khách tự động chuyển đổi các thông báo đến trên luồng HTTP thành các Event đối tượng thích hợp, phân phối chúng đến các trình xử lý sự kiện đã được đăng ký cho các loại sự kiện nếu biết, hoặc tới trên tàu trình xử lý sự kiện nếu không có trình xử lý sự kiện loại cụ thể nào được thiết lập.
Kết luận
HTTP là một giao thức có thể mở rộng rất dễ sử dụng. Cấu trúc máy khách-máy chủ, kết hợp với khả năng thêm tiêu đề, cho phép HTTP phát triển cùng với các khả năng mở rộng của Web.
Mặc dù HTTP/2 thêm một số phức tạp, bằng cách nhúng các thông báo HTTP vào các khung để cải thiện hiệu suất, cấu trúc cơ bản của các thông báo vẫn giữ nguyên kể từ HTTP/1.0. Luồng phiên vẫn đơn giản, cho phép nó được điều tra và gỡ lỗi bằng một trình giám sát thông báo HTTP đơn giản.